GRPO(Group Relative Policy Optimization)
To align Large Language models with human preferences

This is my second blog post in the series of LLM reasoning. After pre-training stage is over reinforcement learning is being used in seconds stage to align the LLM model for particular task like reasoning, tool use, function calling etc. In pre-training stage model gathers language vocabulary and possible patterns from human language but we can’t use it directly or we can’t publish it cause it may generate unsafe, abusive text or it may help people to do wrong things or we can’t use it for any task like reasoning or tool calling cause of it’s inconsistent outputs. This is the time when we moves towards reinforcement learning which helps model to be consistent, safe, polite, capable for tool calling etc.
1. Introduction
RL(Reinforcement Learning) is super powerful mechanism to align the LLM’s with human preferences specifically RLHF(Reinforcement Learning From Human Feedback).
In RLHF we basically trains one reward model. How?
We give the prompt to LLM and gets multiple response. Out of those responses based on results humans assigns different rewards to the responses like good responses will have high reward and bad will have less.
Once we get this data we trains one reward model as human preference predictor and we just use that model in future for reward assignment.
We fine tune the LLM by using PPO to maximize the scores assigned by this learned reward model.
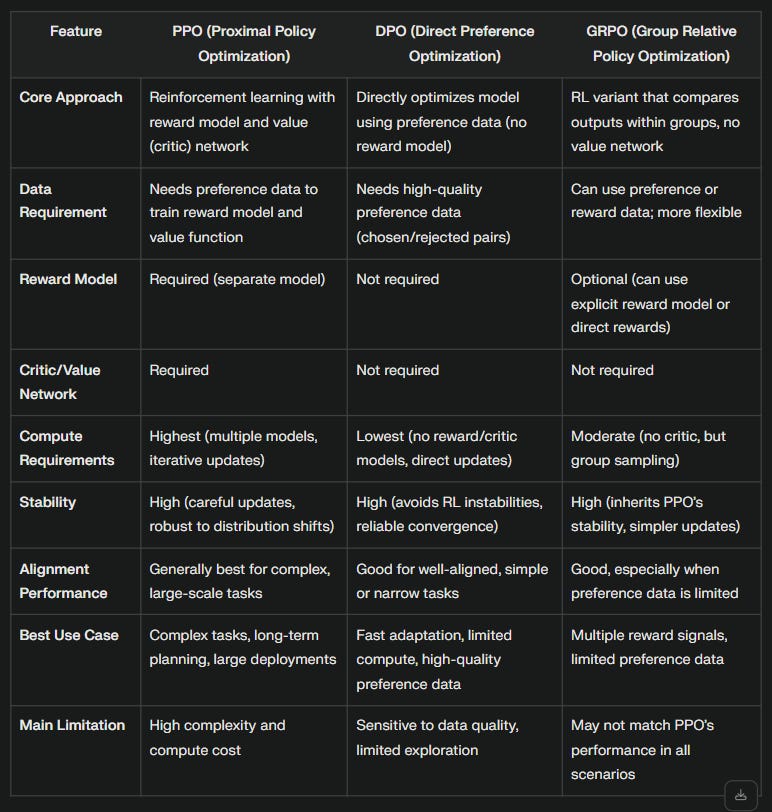
GRPO is a variant of PPO. It showed good results in reasoning ability. It updates model policy based on relative quality of response generated by model for same prompt and evaluated within that group of responses. GRPO eliminates the separate value function network (or "critic") typically required by PPO.
Questions :
What is the difference between GRPO and PPO and DPO?
What is critic exactly?
for all the answers check out blogs question and answer section at the end of blog.
2. Foundations: From Policy Gradients to Preference Optimization
When applying RL to LLMs. Models next token generation process is denoted as follows :
LLM itself acts as the policy denoted by π and model parameters are detonated by θ. Given an input prompt and the history of generated tokens is called state denoted by s. The LLM produces a probability distribution over the vocabulary for the next token which is called the action space denoted by A. An action is denoted by a which involves sampling the next token from this distribution.
This process run multiple times to generate final response and after final response generation completed. The environment provides response R which quantifies the quality of the generated response based on criteria (correctness, helpfulness). The goal of the RL is to optimize the parameters of the model (θ) to maximize the expected cumulative reward over time. which pushed model to generated high quality responses.
Quick Look in the past :
REINFORCE algorithm is a fundamental example of a vanilla PG(Policy Gradient) method. which optimizes the model parameters(θ) towards the expectation. πθ = policy or LLM. Policy Gradient Theorem (REINFORCE/PPO/GRPO) provides expression for gradients of expected rewards. key component of the theorems are Advantage Functions : A(s,a). The advantage quantifies how much better taking a specific action a in state s is compared to the average action expected under the current policy (current model) from that state. Advantage function helps to reduce the variance of the gradient estimates. while vanilla methods like REINFORCE always suffers from variance issue. In REINFORCE method the models weights get updated directly with respect to rewards which can cause performance drop drastically this is called variance issue. PPO emerges to mitigate it. PPO prevents the large updates in the policy directly. Its core feature is a clipped surrogate objective function. This objective uses the probability ratio
aT : Next token predicted at time T.
sT : Prompt given and no. of tokens generated till now.
πθ(aT∣sT) : Current environment state.
πθold(aT∣sT) : Previous state.
3. Definition and core principles
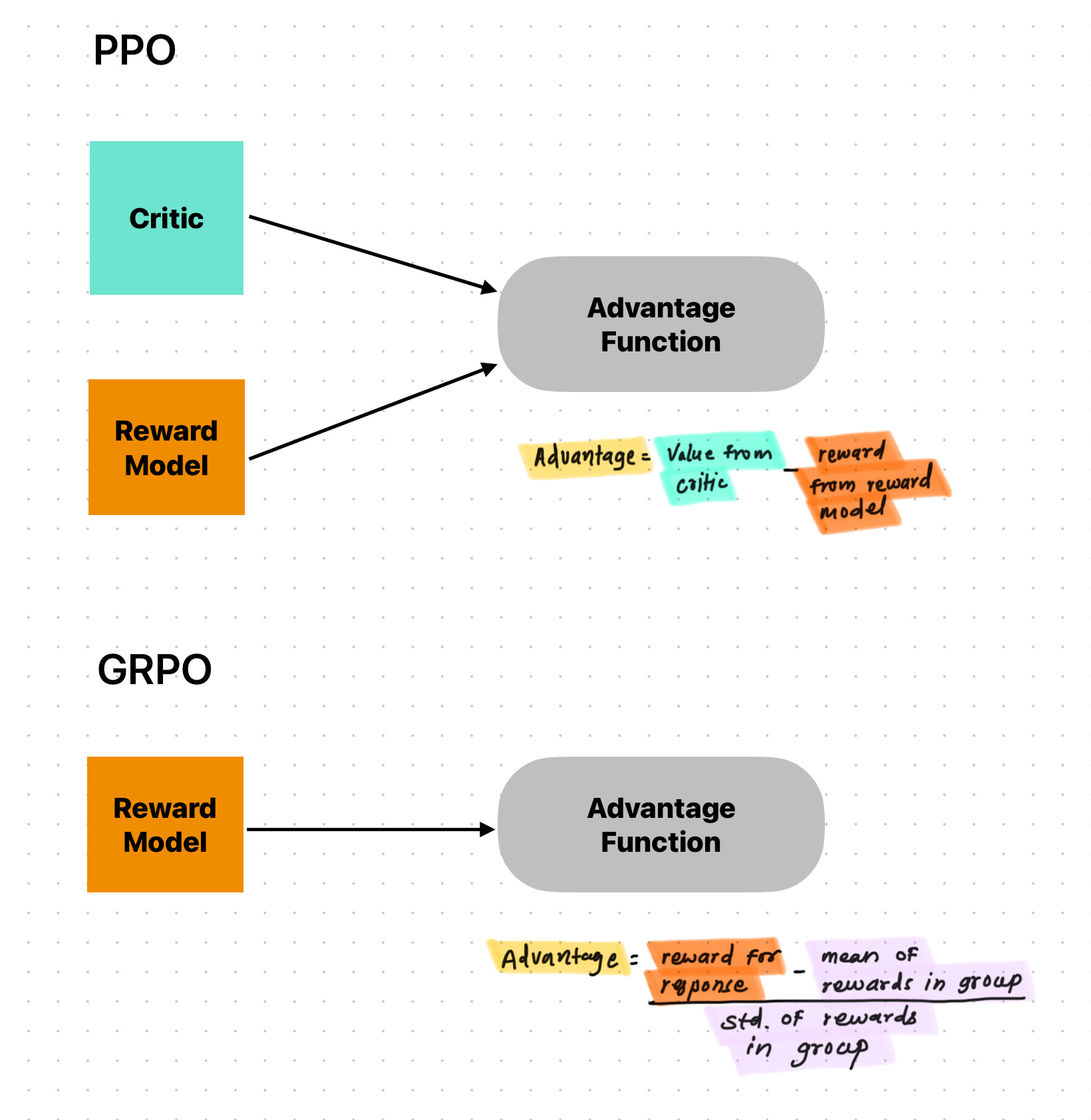
PPO is more generic algorithm which can be used for any system like robotics also but the GRPO is variant developed for LLMs specifically. Both PPO and GRPO are policy optimization algorithm where difference is GR(Group Relative).
what is it? Let’s simulate it for one sample.
We pass one prompt to the model and save it’s multiple responses after that reward model assigns rewards to those group of responses. advantage of a particular response is determined by how it stacks up against its peers generated under the same conditions. While PPO additionally relies on value estimates from critic(model/rule based system). In PPO critic plays crucial role as it helps reducing the variance of policy gradient estimates by providing baseline estimate of the expected return from a given state—against which the actual obtained reward is compared to calculate the advantage. GRPO circumvent this by estimating the necessary baseline directly from the rewards assigned to the group of sampled outputs generated for a given input. Typically, the average reward across the sampled group serves as this empirical baseline. The distinction between PPO and GRPO lies in how the advantage function(A) from the objective function is calculated in both. PPO relies on critic value estimate while GRPO derives the advantage from the relative performance within the sampled group.
What is the exact difference between critic and reward model? → see blogs bottom.
Core mechanism : GRPO workflow
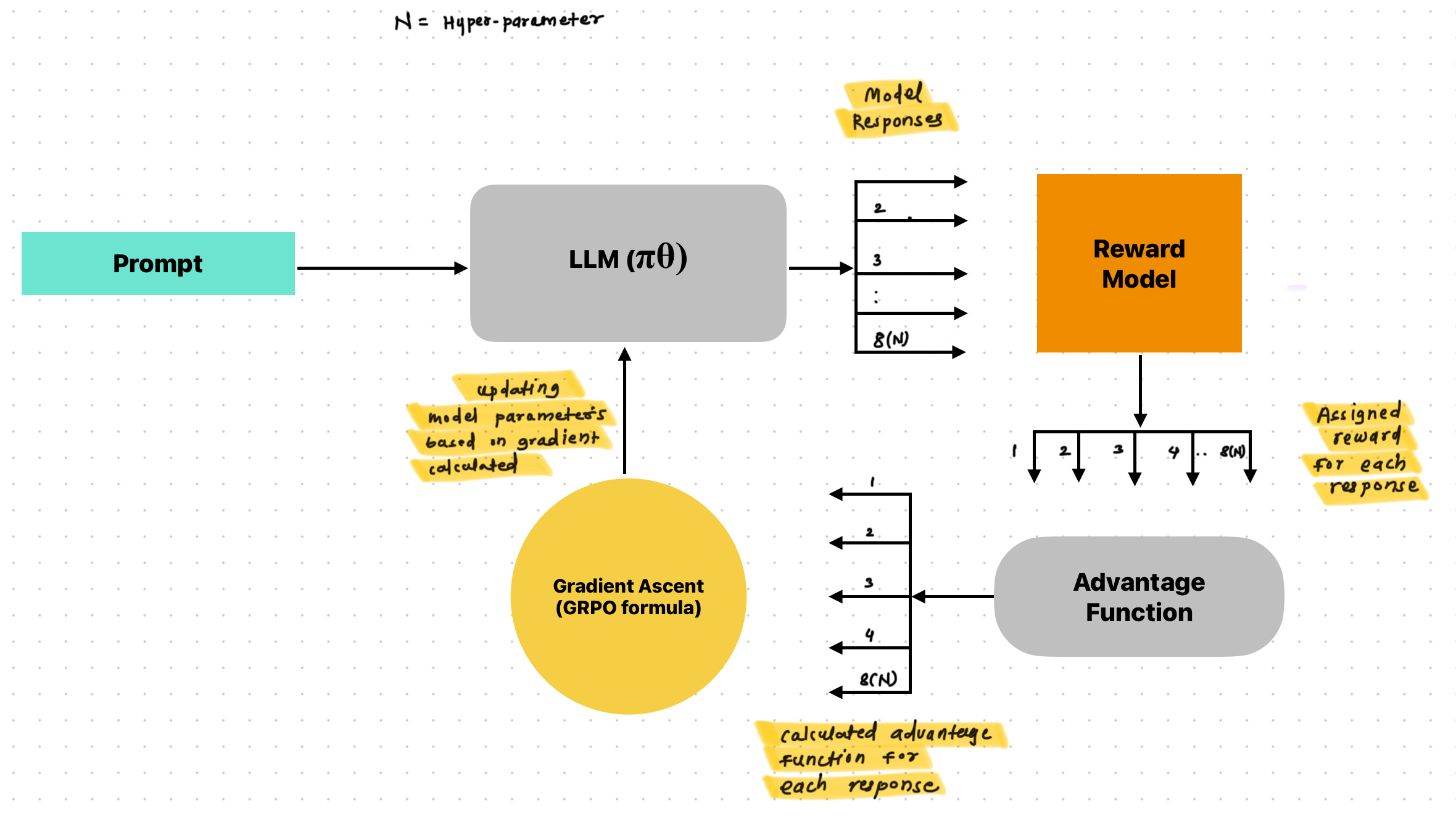
The operational flow of GRPO involves the following key steps.
Generation: For a given input prompt, the current language model policy (πθ) is used to generate multiple (N) candidate output sequences.
Scoring: Each generated output is evaluated using a predefined reward function (which could be rule-based, a learned reward model, or a metric), yielding a scalar reward score for each candidate.
Advantage Calculation: The advantage for each candidate output is calculated based on its reward relative to the other outputs in the same group. This typically involves normalizing the reward, for instance, by subtracting the mean reward of the group and dividing by the standard deviation of the group's rewards.
Policy Update: The parameters of the language model policy are updated using gradient ascent on the GRPO objective function. This update encourages the policy to increase the probability of generating outputs that had a higher relative advantage within their group and decrease the probability of those with lower relative advantage.
The samples which LLM generating should have good quality and it should represent the performance distribution of the current policy else GRPO won’t work well. Like group mean and std won’t give us baseline. The effectiveness of GRPO hinges on the quality and diversity of these samples. If the samples generated are consistently poor or lack diversity, the calculated group mean reward might serve as an unreliable baseline, potentially leading to noisy or misdirected advantage signals and hindering effective learning.
4. Mathematical Formula of GRPO
θ: The parameters of the current policy model πθ being optimized.
πθold: The policy model from the previous training iteration, used for sampling.
q: An input prompt (e.g., a question) sampled from the dataset μ(q).
{oi}i : A group of G output sequences (responses) sampled from the old policy πθold given the prompt q.
∣oi∣: The length (number of tokens) of the i-th output sequence.
oi,t: The t-th token in the i-th output sequence.
oi,<t: The sequence of tokens preceding the t-th token in the i-th output.
The probability ratio comparing the likelihood of generating token oi,t under the current policy versus the old policy.
\( \rho_{i,t}(\theta) = \frac{\pi_{\theta_{\mathrm{old}}}\bigl(o_{i,t}\mid q,\,o_{i,<t}\bigr)} {\pi_{\theta}\bigl(o_{i,t}\mid q,\,o_{i,<t}\bigr)}. \)A^i,t: The estimated advantage for taking action (generating token) oi,t at step t in sequence i.
ϵ: A hyperparameter defining the clipping range (e.g., 0.2), limiting the change in the probability ratio, similar to PPO.
β: A coefficient controlling the strength of the KL divergence penalty.
- \(\begin{align} D_i(\theta) &=\frac{\pi_{\mathrm{ref}}(o_i\,|\,q)}{\pi_\theta(o_i\,|\,q)} -\ln\!\frac{\pi_{\mathrm{ref}}(o_i\,|\,q)}{\pi_\theta(o_i\,|\,q)}-1. \end{align} \)
The Kullback-Leibler (KL) divergence measuring the difference between the current policy πθ and a reference policy πref for the given prompt q.
E[…]: Expectation taken over the distribution of prompts and the outputs sampled from the old policy.
Maximizing this objective encourages generating tokens that lead to high-advantage sequences, while the clipping and KL terms ensure stability.
In the formula we can see the policy updates are clipped and penalized by two terms 1. We are taking min of unclipped advantage-weighted ratio with clipped one. Which helps preventing bigger updates in weights. We choose the clipping hyper parameter (ϵ) here. 2. Kl divergence function which always control the difference between two model old one and current one with its hyper parameter(β).
4.1 Advantage Calculation :
The core evaluation of GRPO lies in calculation of advantage without critic(neural network). Normalizing the rewards obtained within the sampled group {oi}.
DeepSeekMath paper details 2 methods for this
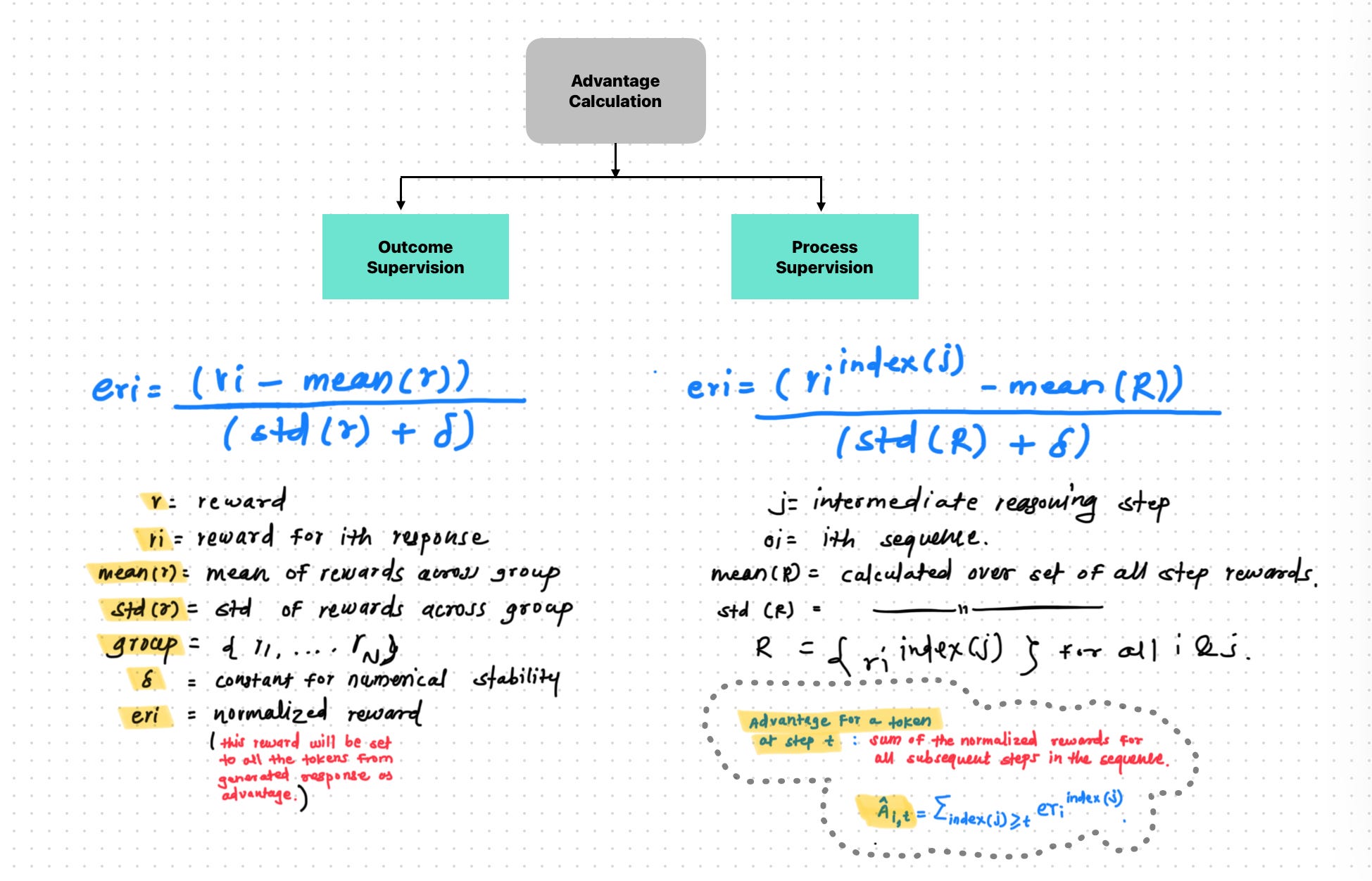
Outcome Supervision :
In this case we assign the advantage to the token of response based on simple normalization formula.
Here we do the calculation of the rearwards at output sequence level like we take the mean snd std across group and then calculate the reward or advantage for perticular response.
Here we don't think about intermediate steps or token generated by model. means we are ignoring the internal thinking of the model.
Process Supervision :
In this case we basically breaks the response in multiple reasoning steps and assign advantage based on the importance of that reasoning step.
Here we first breaks down the model sequnces into sub reasoning steps and then we assign seperate rewards for each step.
then while calculating the final reward for particular output sequence we consider intermediate rewards or summation of them.
This relative measure drives the learning signal.
4.2 KL Divergence Regularization :
The aim of the KL Divergence in the GRPO is avoid bigger updates in the model by limiting the change comparing it with old model or model before starting RL or the model in previous iteration in the RL process.
It avoids catastrophic change in the model and to avoid model from forgetting all the knowledge he gained till that time.
5. Training LLMs with GRPO
The practical implementation of GRPO involves an iterative training loop that leverages its core principles of multi-sampling and group-relative advantage calculation.
5.1. Core training loop
We have already core mechanism or workflow of GRPO in Section 3. This cycle of sampling, scoring, advantage calculation, and policy update is repeated for many iterations or epochs until the model's performance converges or reaches a desired level.
5.2. Data Requirements
For training model with GRPO there are two data requirements.
Prompts : for training model with specific task we required prompts of maths, codes or relative reasoning task prompts.
Preference Data : In the process of GRPO we need either reward pre-trained model or human preference rule based system in the loop to assign rewards to the generated responses. To train this reward model or to setup rule based system we need human preference data.
5.3. Reward function design
A key aspect of GRPO's flexibility is its compatibility with various types of reward functions:
Rule-Based / Deterministic Rewards: As heavily utilized by DeepSeek for reasoning tasks, these functions evaluate responses based on objective, verifiable criteria. Examples include checking if a final mathematical answer matches the ground truth, verifying if generated code compiles and passes tests, ensuring the output adheres to a specific format (e.g., using
<think>...</think>tags), or checking for language consistency in the output. The primary benefits are simplicity, interpretability, and avoidance of reward hacking.Learned Reward Models (RMs): GRPO can integrate with the standard RLHF approach where a separate model is trained to predict scalar rewards, often based on human preference labels. The output score from the RM for each generated response serves as the input reward for the GRPO advantage calculation.
Multi-Label / Multi-Aspect Rewards: Recent research explores training RMs that output multiple scores reflecting different dimensions of quality (e.g., politeness, safety, meaningfulness, actionability). These scores are then aggregated by a weighted sum into a single scalar reward R(s,a) that is fed into the GRPO loop. This allows for better alignment across potentially conflicting objectives.
LLM-as-a-Judge: Another approach involves using a powerful, separate LLM to evaluate the generated responses and assign scores, acting as a proxy for human judgment.
5.4. Computational Aspects
Memory Efficiency: The advantage of GRPO of it’s avoidance of critic model which can of size similar to policy model so avoiding it directly helps saving such model uploading on gpu. A typical PPO setup might involve the policy model, the value/critic model, a reference model for KL calculation, and potentially a separate reward model. GRPO typically requires only the policy model and the reference model, plus potentially a reward model if not using rule-based rewards. This reduction makes it feasible to train larger models or to train on hardware with less VRAM.
Parameter Efficient Fine-Tuning (PEFT): GRPO implementations can be done by PEFT techniques like LoRA (Low-Rank Adaptation). LoRA involves freezing the majority of the pre-trained LLM weights and training only a small number of additional "adapter" parameters. This dramatically reduces the number of trainable parameters and the associated optimizer state memory, further lowering computational costs and enabling fine-tuning on more modest hardware setups.
5.5. Role of Reference Model
A frozen reference model, typically the model checkpoint before RL begins (e.g., the SFT model), plays a crucial role in GRPO training. It serves as the target for the KL divergence penalty term in the objective function. This regularization prevents the policy being trained (πθ) from deviating too drastically from the reference policy (πref), which helps maintain training stability and prevents the model from "forgetting" its general capabilities learned during pre-training or SFT. It acts as an anchor, ensuring that while the model optimizes for the specific RL task, it doesn't drift into undesirable region.
5.6. Multi-Stage Training Pipelines
It is common practice to integrate GRPO within a broader, multi-stage training pipeline rather than using it in isolation. Frequently, an initial phase of Supervised Fine-Tuning (SFT) is performed on instruction-following or task-specific data. This SFT stage provides the model with a strong baseline understanding of the task format and desired behavior. GRPO is then applied subsequently to refine specific capabilities (like mathematical reasoning) or to align the model with preferences (like helpfulness or safety) using reinforcement learning signals. The DeepSeek-R1 pipeline exemplifies this multi-stage approach.
The flexibility in reward function design presents a nuanced picture regarding GRPO's simplicity. While GRPO's core mechanism eliminates the need for a PPO-style critic, achieving significant efficiency gains, the overall complexity depends heavily on the chosen reward source. When verifiable tasks like mathematical correctness allow for simple rule-based rewards, as demonstrated effectively by DeepSeek, the GRPO pipeline is indeed considerably simpler and avoids potential issues like reward hacking associated with learned models. However, aligning LLMs with complex, subjective human values such as helpfulness, harmlessness, or politeness often necessitates the use of learned reward models, potentially trained on human preferences or employing multi-aspect scoring. In these scenarios, while GRPO still avoids the value function, it re-introduces the complexity of training and managing a reward model. Thus, the practical simplicity and efficiency benefits of GRPO are most pronounced when the target behavior can be captured by non-learned reward functions.
6. Conclusion
In this article we have studied the GRPO theoretically like we have covered the the emergence of GRPO, it’s working mechanism, it’s mathematical objective function and stages in tunning the LLM for GRPO. In next blog post we will be exploring it in technical details like planning to train small LLM on open source dataset.
Question Answers
What is critic exactly?
Ans : Critic is separate system or model from reward model which role is to direct model parameters updates towards the final goal than focusing on temporary reward. Compared to reward model which role is to assign rewards to model response directly while critics role in PPO is more wider compared to reward model.
What other methods are there in reinforcement learning?
Ans :
Reinforcement Learning │ ├── Value-Based Methods │ ├── Q-Learning │ ├── Deep Q-Networks (DQN) │ └── Q*-based Methods (Q-LM, Q-Instruct) │ ├── Policy Optimization Methods │ ├── REINFORCE │ ├── PPO (Proximal Policy Optimization) │ ├── GRPO (Generalized Rejection PPO) │ └── DPO (Direct Preference Optimization) │ └── Feedback-Driven Training Pipelines ├── RLHF (Reinforcement Learning from Human Feedback) │ ├── Uses Reward Model │ ├── Uses PPO (typically) │ ├── Can use GRPO (alternatively) │ └── Can be approximated by DPO │ ├── RLAIF (Reinforcement Learning from AI Feedback) │ ├── Uses AI-generated preferences │ ├── Often paired with DPO │ └── Can also use PPO or GRPO │ └── Preference-Based Methods (Reward-Free) ├── DPO ├── SPIN (Scalable Preference Inference) └── Constitutional AI (Rule-based feedback)
Comparison between PPO, DPO and GRPO
Ans :