
LLM Reasoning the Emergent Capability
Decoding the Basics: How LLMs Learn to Think

Reading the title of this blog post, you may be astonished because big tech companies are spending billions of dollars on training LLM reasoning models. So how can reasoning be considered an emergent capability? If you're not surprised, you likely already have a good background in how LLMs work, and it's time to delve deeper. If you are surprised, this article will be a very interesting read for you today. Yes, Chain of Thought is the basic version of LLM reasoning, which is actually an emergent capability of LLMs.
Before going in depth let’s understand some basics about LLM training.
1. Common Steps involved in developing an LLM
1.1 Building
It involves the training LLM on internet dataset. it can containing the web pages, books, Wikipedia articles.
1.2 Training
Training above model for subsequent specialized task like RAG, Reasoning
1.3 Fine Tunning
Fine tunning it for use cases like classification or extraction
2. Reasoning basics
Reasoning is the process in LLMs which actually requires complex, multi-step generations and intermediate steps.
For example:
If the question is about who is the president of some country, it doesn't need LLM reasoning. However, mathematical questions do require reasoning, as they involve multiple intermediate steps like forming equations, filling in values, and calculating outputs. When this approach doesn't work, we can try other methods as well.
4. Methods to improve LLM reasoning skills
As we know, LLMs have the capability to think in a chain-of-thought manner when we add the four magical words 'think step by step.' But that is not enough to solve complex real-world problems. This is why humans are exploring multiple ways to improve LLMs' reasoning capabilities. I am referring to the latest techniques used, especially in the DeepSeek model.
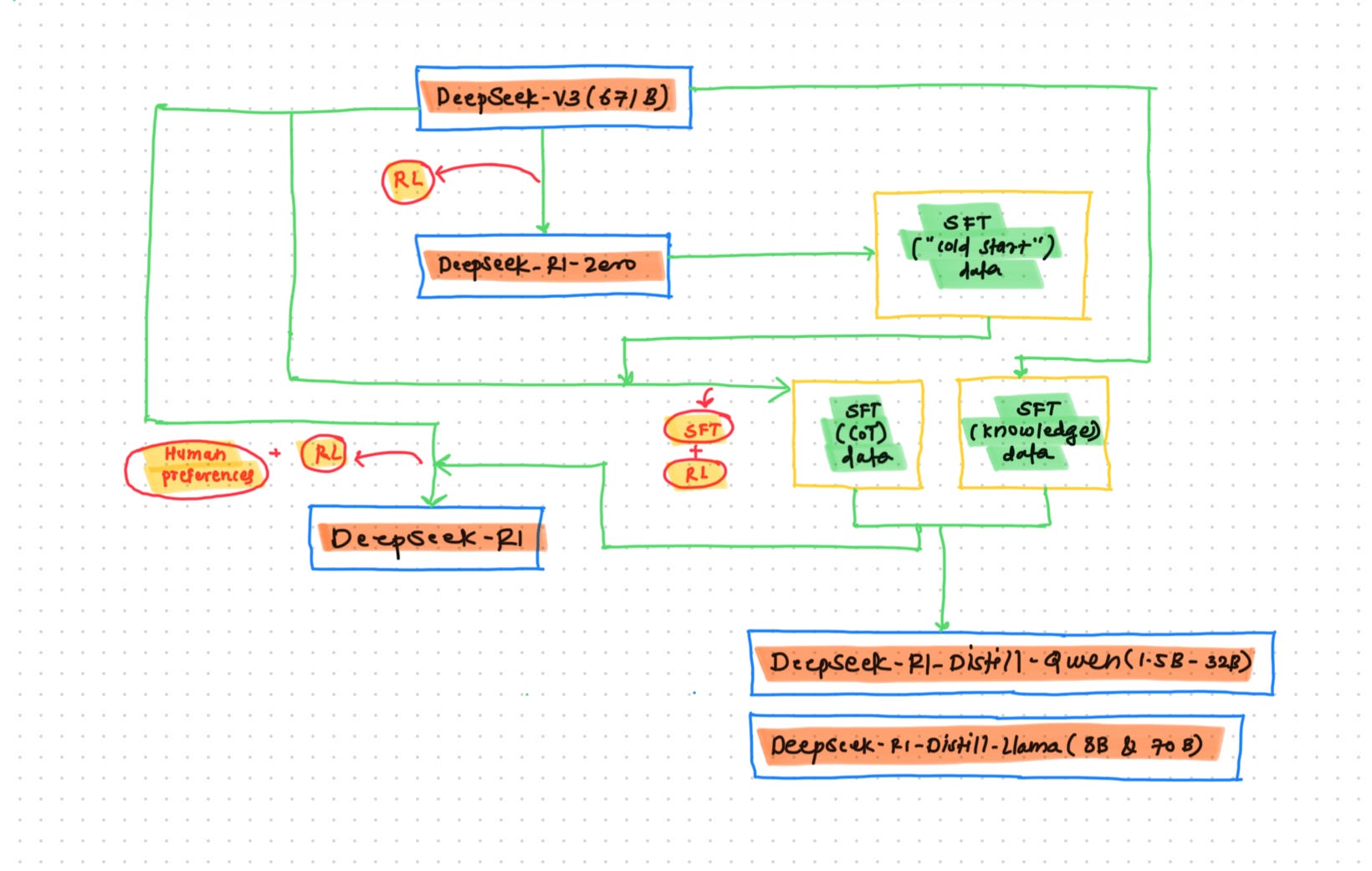
This workflow shows the actual model trained by DeepSeek. Let me explain this workflow first to go into the reasoning techniques.
DeepSeek-V3 is the base model trained by the DeepSeek team on large datasets from the internet. The team performed reinforcement learning on the base model and produced DeepSeek-R1-Zero. This DeepSeek-R1-Zero model was then used to generate SFT (Supervised Fine-Tuning) data to train subsequent models. Using this cold start data, the team performed SFT on the base model and then reinforcement learning, producing one checkpoint for later use in data generation. The team used this checkpoint to produce Chain of Thought data and knowledge data, which were then used for the final DeepSeek R1 training that we are using now. The team used the same data and checkpoint to perform knowledge distillation in smaller models named Qwen and LLaMA.
Overall, the above process can be broken down into 4 steps, which are basically core reasoning model development
1. Inference time scaling
Inference time scaling involves allocating more computational resources to a model during inference, allowing it to "think" more before responding. This concept mirrors human reasoning, where time is taken to deliberate before speaking. Techniques like chain-of-thought (CoT) prompting, voting mechanisms, and beam search are often used in inference scaling to enhance model reasoning capabilities.
Voting Mechanism
In voting, multiple responses are generated by the model, and the best one is selected based on a majority or weighted decision. This approach can improve accuracy by aggregating diverse outputs but may reduce preference diversity if not carefully managed.
Beam Search
Beam search is a heuristic algorithm that generates multiple candidate outputs (based on probabilities) and prunes less promising ones at each step. The "beam width" determines how many candidates are retained. A larger beam width increases accuracy but at the cost of higher computation. It is widely used in NLP tasks like translation and summarization to balance efficiency and quality.
OpenAI's o1 and o3 models likely leverage such mechanisms for better reasoning, while DeepSeek focuses on enhancing reasoning through reinforcement learning and fine-tuning rather than inference scaling.
2. Pure reinforcement learning
Pure reinforcement learning generally has two stages in the training pipeline: supervised fine-tuning and reinforcement learning. In supervised fine-tuning, we prepare data consisting of questions and responses, where the answers to the questions are detailed steps in the solution.
3. Supervised fine tuning and reinforcement learning.
In the above diagram, if you look, the DeepSeek team is referring to something called "cold data." It is the dataset generated by the model DeepSeek-R1-Zero. The team used this data to perform SFT later for the base model (DeepSeek V3). After that, the team again performed RL which includes 2 types of rewards:
Accuracy Reward: The DeepSeek team used LeetCode Compiler to check the accuracy of the code generated by their checkpoint.
Format reward: They used this reward to check the output formats generated by the model.
Now again, the DeepSeek team used the above checkpoint to generate more data for DeepSeek R1 training. The data consists of:
600K Chain-of-Thought (CoT) SFT examples
200K knowledge-based SFT examples
The team used the above to fine-tune the base model again, and that's the model we are using right now, which is DeepSeek R1.
4. Pure supervised fine tuning and reinforcement learning
This involves distilling the large model's knowledge into smaller models. Generally, we match the probability distributions of both models using KL-Divergence loss, but for the DeepSeek models, they have performed some Supervised Fine-Tuning (SFT) to achieve this. They generated data using a previous model checkpoint and used DeepSeek R1 to distill it into smaller models like DeepSeek-R1-Distill-Qwen (1.5B-32B) and DeepSeek-R1-Distill-Llama (8B & 70B). They used logins from the DeepSeek R1 model for distillation and SFT data from the previous checkpoint.
This blog is all about the state of reasoning models in the current stage of the LLM era. There are lots of research efforts going on daily, and we will keep learning about them. Just a heads-up on the recent Kaggle competition related to reasoning models named AIMO (AI Mathematical Olympiad). Take a look at the winners' write-ups on actual reasoning training we can perform for mathematical problem solving.
My upcoming blog post will focus on GRPO, offering a more detailed and technical perspective. Stay tuned!
References :