
Understanding Model Memory Calculations
Breaking Down GPU Memory Usage: Understanding Model Parameters, Optimizer States, Gradients, and Activations

Training large machine learning models, especially deep learning models, requires significant memory resources. Understanding how memory is utilized during training can help optimize configurations and avoid out-of-memory errors. This post explains the key components of memory consumption during model training and the formulas used to calculate them.
Components of Memory Usage
During training, the memory is primarily consumed by the following components:
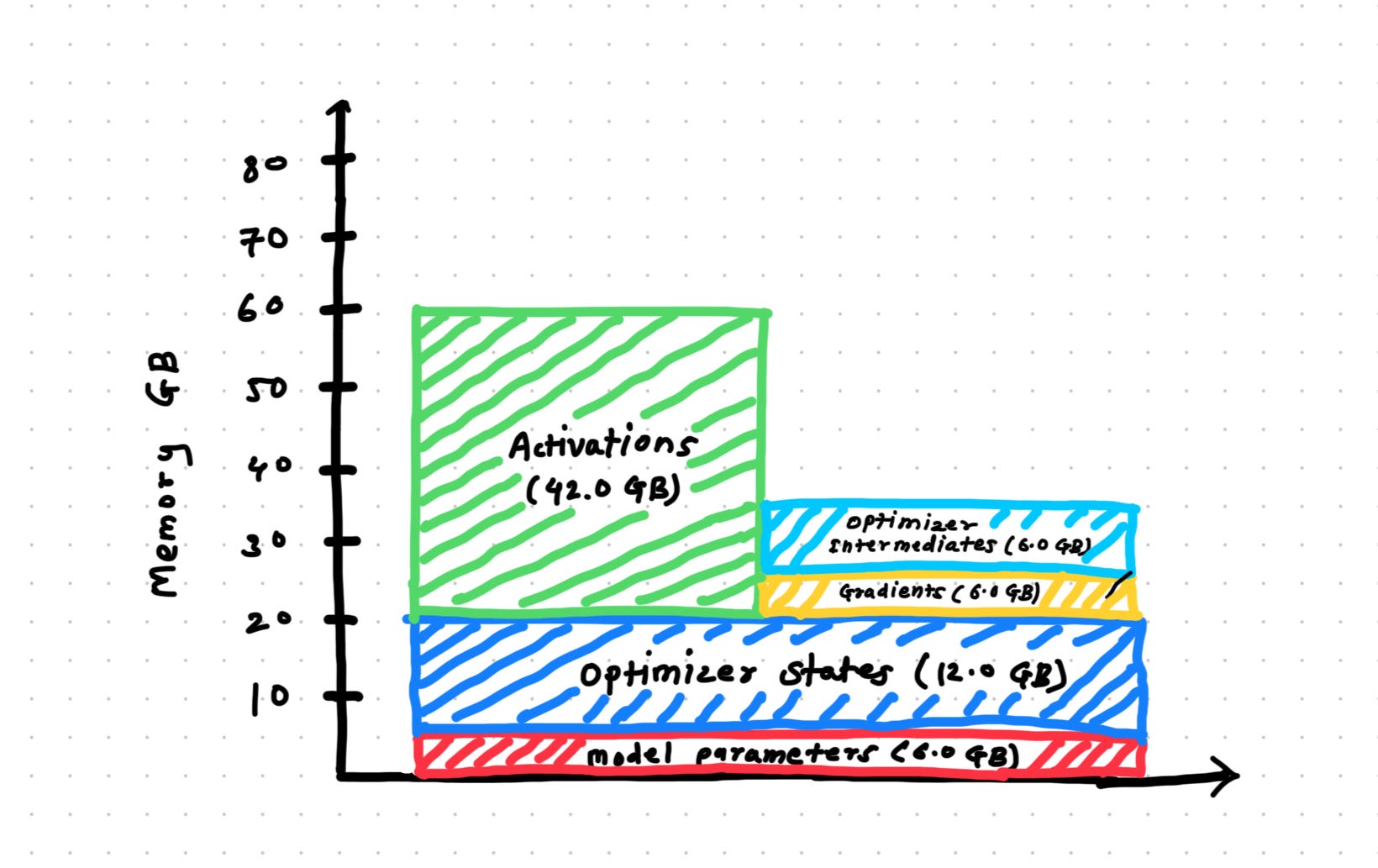
Model Parameters: These are the weights and biases of the model, which are stored in memory throughout the training process.
Optimizer States: Optimizers like Adam maintain additional states such as momentum and variance for gradient updates, which can significantly increase memory requirements.
Gradients: Gradients are computed during backpropagation and stored temporarily for weight updates.
Activations: These are intermediate outputs of each layer during the forward pass, stored for use in backpropagation.
Optimizer Intermediates: To update the parameters, the optimizer temporarily stores intermediate values
How GPU Gets Utilized During Model Training
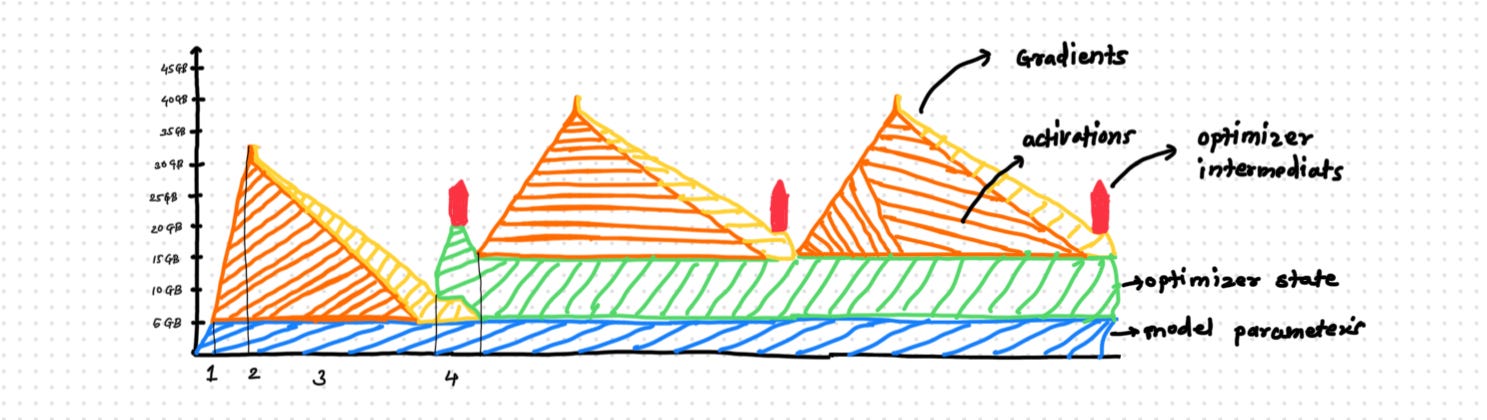
GPU usage during model training can be broken down into four main stages: model initialization, forward pass, backward pass, and optimizer step. Here's a detailed explanation with color-coded references to visualize GPU memory utilization:
1. Model Initialization (Blue Zone)
The model is loaded into GPU memory at the start of training.
This includes storing all model parameters.
Example code snippet:
AutoModelForCausalLM.from_pretrained("Qwen/Qwen2.5-1.5B").to("cuda")The green zone in the graph represents GPU memory allocated for model parameters.
2. Forward Pass (Orange Zone)
During the forward pass, activations are computed layer by layer and stored temporarily on the GPU.
These activations grow as you move deeper into the network until reaching the final layer.
Loss is calculated at this stage when activation memory usage peaks.
Example code snippet:
outputs = model(inputs)The orange zone in the graph represents GPU memory used for activations.
3. Backward Pass (Yellow Zone)
Gradients are calculated during backpropagation using:
loss.backward()The yellow zone represents GPU memory allocated for gradients.
As gradients are calculated, activations are discarded layer by layer to free up memory.
This results in a shrinking yellow region as backpropagation progresses.
4. Optimizer Step (Green Zone)
Once gradients are computed, the optimizer updates model weights using:
optimizer.step()Optimizer states require additional GPU memory (2X model size). These states remain allocated until training ends.
After updating weights, both gradients and optimizer intermediates are freed from memory.
Iterative Process
This cycle repeats for every batch and epoch defined in the training configuration.
Memory Calculation Formulas
The memory requirements for each component can be estimated using the following formulas:
1. Model Memory
This is the memory required to store the model's parameters:
Model Memory = N × P
Where:
N: Number of parameters in the model.
P: Precision in bytes (e.g., 4 bytes for float32, 2 bytes for float16).
2. Optimizer State
Optimizers like Adam require additional memory to store states such as momentum and variance:
Optimizer State = 2 × N × P
For simpler optimizers like SGD without momentum, this requirement may be lower.
3. Gradients
Gradients are computed for each parameter during backpropagation:
Gradients = N × P
4. Optimizer Intermediates
Some optimizers require temporary storage for intermediate calculations:
Optimizer Intermediates = N × P
5. Activations
Activations depend on the number of tokens processed during training:
Activations = A × B × L × P
Where:
A: Activations per token, estimated using a heuristic:
A= 4.6894 × 10 − 4 × N + 1.8494 × 106
B: Batch size (number of samples in one forward/backward pass).
L: Sequence length (number of tokens per sample).
P: Precision in bytes.
Key Insights
Precision Matters: Using lower precision (e.g., float16) can significantly reduce memory usage compared to float32.
Optimizer Choice: Stateful optimizers like Adam require more memory than stateless ones like SGD without momentum.
Gradient Checkpointing: This technique reduces activation memory by recomputing activations during backpropagation instead of storing them.
Understanding these calculations helps in optimizing model configurations, selecting appropriate hardware, and enabling techniques like gradient checkpointing or optimizer state Sharding to reduce memory usage.